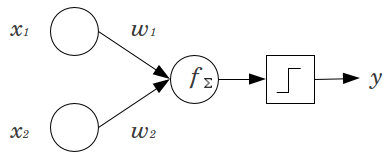
In this schema, an object (pattern) is represented by a vector x and its characteristics (features) are represented by the vector's elements x_1 and x_2. We call the vector w, with elements w_1 and w_2, the weights vector. The values x_1 and x_2 are the input of the Perceptron. When we activate the Perceptron each input is multiplied by the respective weight and then summed. This produces a single value that it is passed to a threshold step function. The output of this function is the output of the Perceptron. The threshold step function has only two possible output: 1 and -1. Hence, when it is activated his reponse indicates that x belong to the first class (1) or the second (-1).
A Perceptron can be trained and we have to guide his learning. In order to train the Perceptron we need something that the Perceptron can imitate, this data is called train set. So, the perceptron learns as follow: an input pattern is shown, it produces an output, compares the output to what the output should be, and then adjusts its weights. This is repeated until the Perceptron converges to the correct behavior or a maximum number of iteration is reached.
The following Python class implements the Percepron using the Rosenblatt training algorithm.
from pylab import rand,plot,show,norm
class Perceptron:
def __init__(self):
""" perceptron initialization """
self.w = rand(2)*2-1 # weights
self.learningRate = 0.1
def response(self,x):
""" perceptron output """
y = x[0]*self.w[0]+x[1]*self.w[1] # dot product between w and x
if y >= 0:
return 1
else:
return -1
def updateWeights(self,x,iterError):
"""
updates the weights status, w at time t+1 is
w(t+1) = w(t) + learningRate*(d-r)*x
where d is desired output and r the perceptron response
iterError is (d-r)
"""
self.w[0] += self.learningRate*iterError*x[0]
self.w[1] += self.learningRate*iterError*x[1]
def train(self,data):
"""
trains all the vector in data.
Every vector in data must have three elements,
the third element (x[2]) must be the label (desired output)
"""
learned = False
iteration = 0
while not learned:
globalError = 0.0
for x in data: # for each sample
r = self.response(x)
if x[2] != r: # if we have a wrong response
iterError = x[2] - r # desired response - actual response
self.updateWeights(x,iterError)
globalError += abs(iterError)
iteration += 1
if globalError == 0.0 or iteration >= 100: # stop criteria
print 'iterations',iteration
learned = True # stop learning
Perceptrons can only classify data when the two classes can be divided by a straight line (or, more generally, a hyperplane if there are more than two inputs). This is called linear separation. Here is a function that generates a linearly separable random dataset.def generateData(n): """ generates a 2D linearly separable dataset with n samples. The third element of the sample is the label """ xb = (rand(n)*2-1)/2-0.5 yb = (rand(n)*2-1)/2+0.5 xr = (rand(n)*2-1)/2+0.5 yr = (rand(n)*2-1)/2-0.5 inputs = [] for i in range(len(xb)): inputs.append([xb[i],yb[i],1]) inputs.append([xr[i],yr[i],-1]) return inputsAnd now we can use the Perceptron. We generate two dataset, the first one is used to train the classifier (train set), and the second one is used to test it (test set):
trainset = generateData(30) # train set generation perceptron = Perceptron() # perceptron instance perceptron.train(trainset) # training testset = generateData(20) # test set generation # Perceptron test for x in testset: r = perceptron.response(x) if r != x[2]: # if the response is not correct print 'error' if r == 1: plot(x[0],x[1],'ob') else: plot(x[0],x[1],'or') # plot of the separation line. # The separation line is orthogonal to w n = norm(perceptron.w) ww = perceptron.w/n ww1 = [ww[1],-ww[0]] ww2 = [-ww[1],ww[0]] plot([ww1[0], ww2[0]],[ww1[1], ww2[1]],'--k') show()The script above gives the following result:

The blue points belong to the first class and the red ones belong to the second. The dashed line is the separation line learned by the Perceptron during the training.
it seems like current implementation doesn't work with dots, scattered it full quadrant [-1,1]x[-1,1].
ReplyDeleteI have referenced your code and shared the modified code on Github(https://github.com/Honghe/perceptron).
ReplyDeleteIf your don't like please inform me.
Thx!
No problem Honge!
DeleteHow would you modify the code to plot for a vector with 3 features instead of 2
ReplyDeleteYou have to draw a 3D plot. Maybe this could help you:
Deletehttp://glowingpython.blogspot.it/2012/12/3d-stem-plot.html
Pay attention, in this case the separation surface is a plane and not a line.
Thank you, that was helpful. How would you calculate the z cordinate ie. "ww3" following your example. Thank you for your time.
ReplyDeleteYou should find the plane orthogonal to the vector percepton.w. Let me know if you succeed :)
Delete:-) will try, thanks
ReplyDeleteCool ... Very nicely blogged ...
ReplyDeleteWhat can I do if I have a 4 class data with x and y features?
ReplyDeleteHi, you can use a one vs all strategy: https://en.wikipedia.org/wiki/Multiclass_classification
DeleteI'd recommend you to use the sklearn implementation: http://scikit-learn.org/stable/modules/generated/sklearn.neural_network.MLPClassifier.html
I would like to use your perceptron code as part of demonstration code included here (in draft form):
ReplyDeletehttps://github.com/jgvfwstone/DeepLearningEngines/blob/master/DeepLearningEnginesCode/Python/Ch03_Perceptron
Please email me at j.v.stone@sheffield.ac.uk
regards,
Jim